
개발자의 스터디 노트
샘플과 타깃의 인코딩 본문
1. 원-핫 표현
- 0 벡터에서 시작해 문장이나 문서에 등장하는 단어에 상응하는 원소를 1로 설정합니다.
아래 두문장을 예로 들면,
Time flies like an arrow.
Fruit flies like a banana.
각 문장을 토큰(token)으로 나누고 구두점을 무시한 다음 모두 소문자로 바꾸면 어휘 사전(vocabulary)이 되고 어휘 사전의 크기는 다음과 같이 8이 됩니다.
{time, fruit, flies, like, a, an, arrow, banana}
따라서 각 단어를 8차원 원-핫 벡터로 표현할 수 있습니다.

구, 문장, 문서의 원-핫 벡터는 이를 구성하는 단어의 원-핫 표현을 단순하게 논리합(logical OR)한 것입니다.
위 표를 참고하여 like a banana의 이진 인코딩은 [0, 0, 0, 1, 1, 0, 0, 1] 입니다.
사이킷런을 사용하여 원-핫 벡터 또는 이진 표현 만들기
from sklearn.feature_extraction.text import CountVectorizer
import seaborn as sns
corpus = ['Time files like an arrow.',
'Fruit flies like a banana.']
one_hot_vectorizer = CountVectorizer(binary=True)
one_hot = one_hot_vectorizer.fit_transform(corpus).toarray()
vocab = one_hot_vectorizer.get_feature_names()
sns.heatmap(one_hot, annot=True, cbar=False, xticklabels=vocab, yticklabels=['Sentence 1', 'Sentence 2'])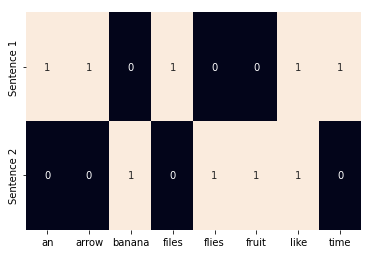
# CountVectorizer 클래스에서 binary=True 로 지정해서 원-핫 인코딩 변환
# binary 매개변수의 기본값은 False로 단어 등장 횟수를 기록한 TF표현을 만듭니다.
# 또 이 클래스는 기본적으로 글자 하나로 이루어진 단어를 무시합니다.
# 이 때문에 단어 a가 없습니다.
# CountVectorizer는 희소 행렬(sparse matrix)을 반화하므로 toarray()메서드를 사용해 밀집행렬(dense matrix)로 바꿔 출력했습니다.
2. TF표현
- 구, 문장, 문서의 TF표현은 단순히 소속 단어의 원-핫 표현을 합해 만듭니다. 예를 들어 앞에서 언급한 원-핫 인코딩 방식을 사용한 Fruit flies like time flies a fruit의 TF표현은 다음과 같습니다.
[1, 2, 2, 1, 1, 0, 0, 0] 각 원소는 해당 단어가 문장(말뭉치)에 등장하는 횟수입니다.
단어 w의 TF는 TF(w)라고 표기합니다.
3. TF-IDF표현
- 특허 문서 묶음이 있다고 가정해 봅시다. 문서 대부분에 'claim', 'system', 'method', 'procedure'같은 단어가 여러 번 반복해서 나올 것이라고 예상할 수 있습니다. TF는 등장 횟수에 비례하여 단어에 가중치를 부여합니다. 하지만 'claim'같이 흔한 단어에는 특정 특허와 관련한 어떠한 정보다 담겨있지 않습니다.
반대로 희귀한 단어(ex.tetrfluoroethylene 테트라플루오로에틸렌)는 자주 나오지 않지만 특허 문서의 특징을 잘 나타냅니다. 이러한 상황에는 역문서 빈도(Inverse-Document-Frequency IDF)가 적합합니다.
TF-IDF 점수는
TF와 IDF를 곱한 TF(w)*IDF(W)입니다.
사이킷런을 사용해 TF-IDF 표현 만들기
from sklearn.feature_extraction.text import TfidfVectorizer
import seaborn as sns
tfidf_vectorizer = TfidfVectorizer()
tfidf = tfidf_vectorizer.fit_transform(corpus).toarray()
sns.heatmap(tfidf, annot=True, cbar=False, xticklabels=vocab, yticklabels=['Sentence 1','Sentence 2'])
** 딥러닝의 목적은 표현 학습이므로 보통 TF-IDF와 같이 경험적인 방법으로 입력을 인코딩하지 않습니다. 주로 정수 인덱스를 사용한 원-핫 인코딩과 특수한 '임베딩 룩업(EMBEDDING LOOKUP'층으로 신경망의 입력을 구성합니다.
TF-IDF 더 알아보기
4) TF-IDF(Term Frequency-Inverse Document Frequency)
이번에는 DTM 내에 있는 각 단어에 대한 중요도를 계산할 수 있는 TF-IDF 가중치에 대해서 알아보겠습니다. TF-IDF를 사용하면, 기존의 DTM을 사용하는 것보다 보 ...
wikidocs.net
'파이썬 > 파이토치 자연어처리' 카테고리의 다른 글
| 텐서의 연산 (0) | 2022.02.08 |
|---|---|
| 텐서를 만들어 봅시다. (0) | 2022.02.08 |
| 지도학습이란? (0) | 2022.02.08 |
| 파이토치를 설치 해 봅시다. (0) | 2022.02.07 |
| 아나콘다 가상환경 생성하고 Jupyter NoteBook 설치 (0) | 2022.02.07 |

