
개발자의 스터디 노트
태스크간 의존성 정의 본문
1. 의존성 정의
- with 구문을 사용하여 좀더 깔끔한 DAG를 작성할 수 있습니다.
import airflow
from airflow import DAG
from airflow.operators.dummy import DummyOperator
with DAG(
dag_id="01_start",
start_date=airflow.utils.dates.days_ago(3),
schedule_interval="@daily",
) as dag:
start = DummyOperator(task_id="start")
fetch_sales = DummyOperator(task_id="fetch_sales")
clean_sales = DummyOperator(task_id="clean_sales")
fetch_weather = DummyOperator(task_id="fetch_weather")
clean_weather = DummyOperator(task_id="clean_weather")
join_datasets = DummyOperator(task_id="join_datasets")
train_model = DummyOperator(task_id="train_model")
deploy_model = DummyOperator(task_id="deploy_model")
start >> [fetch_sales, fetch_weather] #Fan-in 의존성
fetch_sales >> clean_sales # 선형 의존성
fetch_weather >> clean_weather # 선형 의존성
[clean_sales, clean_weather] >> join_datasets # Fan-out 의존성
join_datasets >> train_model >> deploy_model # 선형 의존성
# DummyOperator 더미 오퍼레이터 : 아무것도 수행하지 않는 오퍼레이터,
# 아무것도 실행하지는 않으나 성공적으로 실행된것으로 간주하여 다음 단계로 진행됩니다.
# 복잡한 작업 흐름을 구현하는데 사용할 수 있습니다.- 일반적인 선형 의존성 정의와 1:대인 Fan-in 의존성, 다:1 인 Fan-out 의존성 정의를 확인할 수 있습니다.
- DummyOperator를 활용하면 복잡한 흐름을 구현할 수 있습니다.
- 의존성 그래프
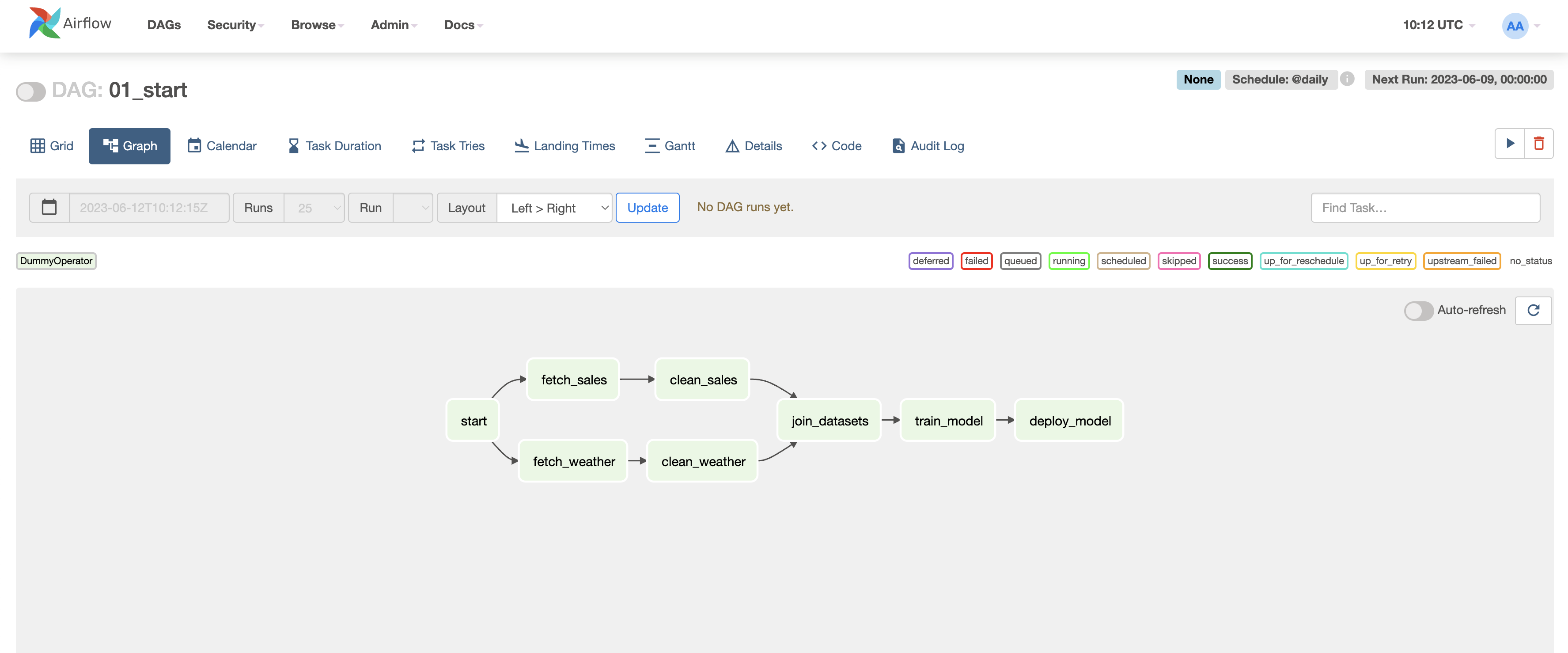
2. 브랜치 하기
- 태스크 내에서 브랜치 하기
import airflow
from airflow import DAG
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import PythonOperator
ERP_CHANGE_DATE = airflow.utils.dates.days_ago(1)
# 수집 태스크 내에서 조건별로 브랜치하기
def _fetch_sales(**context):
if context["execution_date"] < ERP_CHANGE_DATE:
_fetch_sales_old(**context)
else:
_fetch_sales_new(**context)
def _fetch_sales_old(**context):
print("Fetching sales data (OLD)...")
def _fetch_sales_new(**context):
print("Fetching sales data (NEW)...")
# 정제 태스크 내에서 조건별로 브랜치하기
def _clean_sales(**context):
if context["execution_date"] < airflow.utils.dates.days_ago(1):
_clean_sales_old(**context)
else:
_clean_sales_new(**context)
def _clean_sales_old(**context):
print("Preprocessing sales data (OLD)...")
def _clean_sales_new(**context):
print("Preprocessing sales data (NEW)...")
with DAG(
dag_id="02_branch_function",
start_date=airflow.utils.dates.days_ago(3),
schedule_interval="@daily",
) as dag:
start = DummyOperator(task_id="start")
fetch_sales = PythonOperator(task_id="fetch_sales", python_callable=_fetch_sales)
clean_sales = PythonOperator(task_id="clean_sales", python_callable=_clean_sales)
fetch_weather = DummyOperator(task_id="fetch_weather")
clean_weather = DummyOperator(task_id="clean_weather")
join_datasets = DummyOperator(task_id="join_datasets")
train_model = DummyOperator(task_id="train_model")
deploy_model = DummyOperator(task_id="deploy_model")
start >> [fetch_sales, fetch_weather]
fetch_sales >> clean_sales
fetch_weather >> clean_weather
[clean_sales, clean_weather] >> join_datasets
join_datasets >> train_model >> deploy_model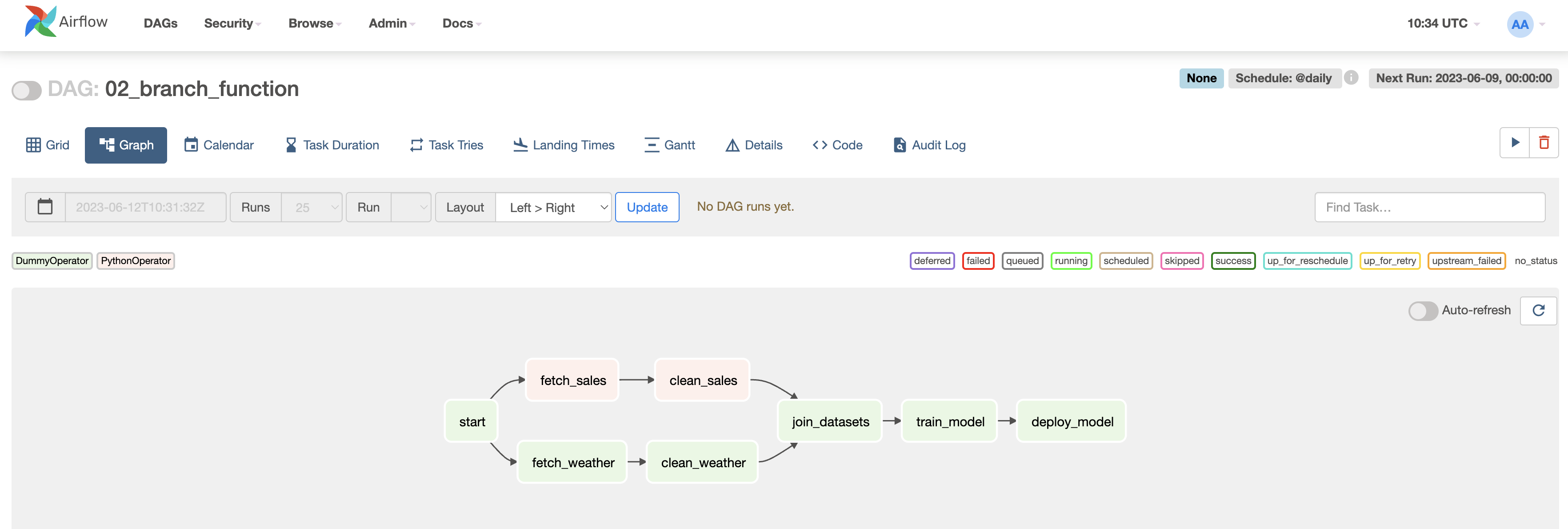
- 브랜치가 태스크 내부에 숨겨져 있어 작업이 명시적이지 않습니다.
3. DAG 내부에서 브랜치하기
import airflow
from airflow import DAG
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import PythonOperator, BranchPythonOperator
ERP_CHANGE_DATE = airflow.utils.dates.days_ago(1)
# 태스크 이름을 리턴하여 명시적으로 브랜치를 나눌수 있게 만든 함수 입니다.
def _pick_erp_system(**context):
if context["execution_date"] < ERP_CHANGE_DATE:
return "fetch_sales_old"
else:
return "fetch_sales_new"
def _fetch_sales_old(**context):
print("Fetching sales data (OLD)...")
def _fetch_sales_new(**context):
print("Fetching sales data (NEW)...")
def _clean_sales_old(**context):
print("Preprocessing sales data (OLD)...")
def _clean_sales_new(**context):
print("Preprocessing sales data (NEW)...")
with DAG(
dag_id="03_branch_dag",
start_date=airflow.utils.dates.days_ago(3),
schedule_interval="@daily",
) as dag:
start = DummyOperator(task_id="start")
# BranchPythonOperator 을 이용하여 명시적으로 브랜치를 나눌수 있습니다.
pick_erp_system = BranchPythonOperator(
task_id="pick_erp_system", python_callable=_pick_erp_system
)
fetch_sales_old = PythonOperator(
task_id="fetch_sales_old", python_callable=_fetch_sales_old
)
clean_sales_old = PythonOperator(
task_id="clean_sales_old", python_callable=_clean_sales_old
)
fetch_sales_new = PythonOperator(
task_id="fetch_sales_new", python_callable=_fetch_sales_new
)
clean_sales_new = PythonOperator(
task_id="clean_sales_new", python_callable=_clean_sales_new
)
fetch_weather = DummyOperator(task_id="fetch_weather")
clean_weather = DummyOperator(task_id="clean_weather")
# Using the wrong trigger rule ("all_success") results in tasks being skipped downstream.
# join_datasets = DummyOperator(task_id="join_datasets")
# 업스트림의 태스크중 하나를 건너뛰더라도 계속 트리거가 진행되도록 트리거 규칙 변경
# trigger_rule="none_failed"
join_datasets = DummyOperator(
task_id="join_datasets",
trigger_rule="none_failed"
)
train_model = DummyOperator(task_id="train_model")
deploy_model = DummyOperator(task_id="deploy_model")
start >> [pick_erp_system, fetch_weather]
pick_erp_system >> [fetch_sales_old, fetch_sales_new]
fetch_sales_old >> clean_sales_old
fetch_sales_new >> clean_sales_new
fetch_weather >> clean_weather
[clean_sales_old, clean_sales_new, clean_weather] >> join_datasets
join_datasets >> train_model >> deploy_model
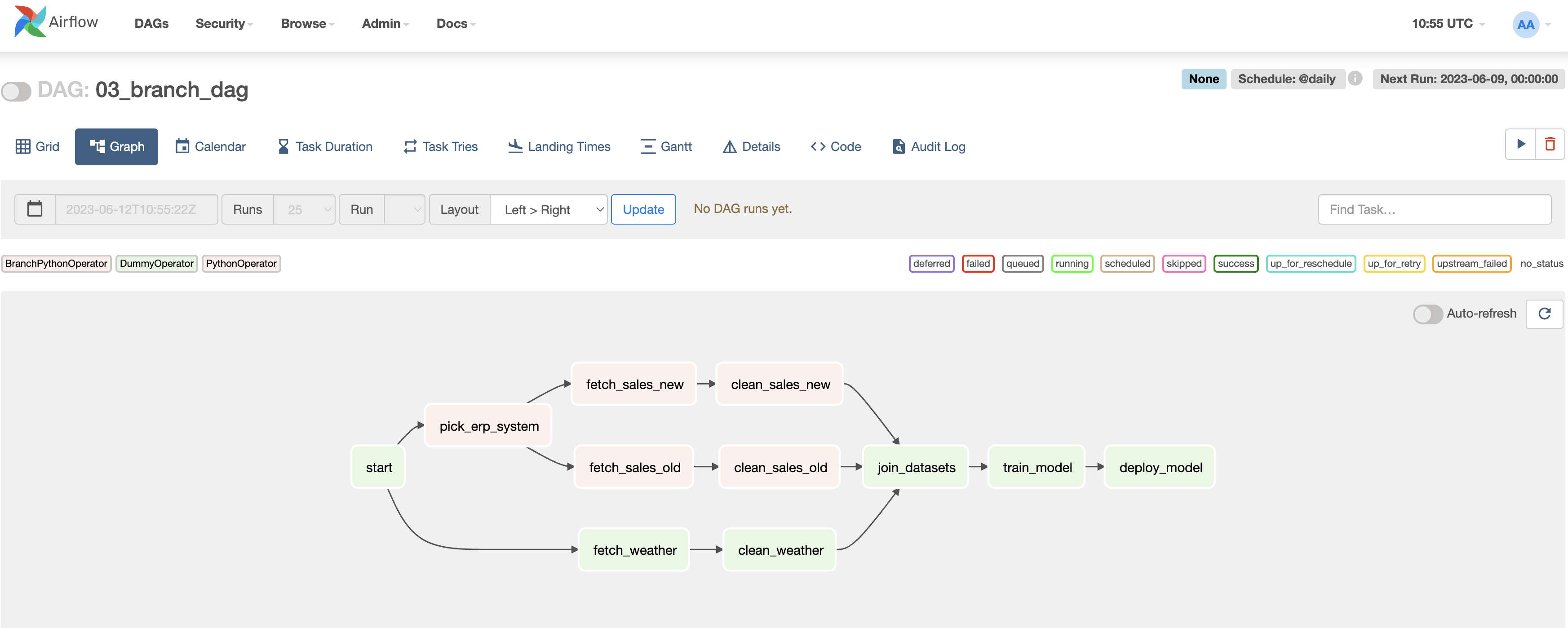
- BranchPythonOperator 을 통해 명시적으로 브랜치를 나눌 수 있습니다.
- trigger_rule="none_failed" 규칙을 변경하여 업스트림의 태스크중 하나를 건너뛰더라도 계속 트리거 진행되도록 할 수 있습니다.
- 트리거 규칙을 변경하지 않는다면 브랜치된 업스트림의 태스크들이 모두 성공이 되지 않아 join_datasets 태스크와 모든 다운 스트림 태스크가 실행되지 않습니다.
- 명확성을 위해 더미 조인 태스크 추가
join_erp = DummyOperator(task_id="join_erp_branch", trigger_rule="none_failed")
fetch_weather = DummyOperator(task_id="fetch_weather")
clean_weather = DummyOperator(task_id="clean_weather")
join_datasets = DummyOperator(task_id="join_datasets")
train_model = DummyOperator(task_id="train_model")
deploy_model = DummyOperator(task_id="deploy_model")
start >> [pick_erp_system, fetch_weather]
pick_erp_system >> [fetch_sales_old, fetch_sales_new]
fetch_sales_old >> clean_sales_old
fetch_sales_new >> clean_sales_new
[clean_sales_old, clean_sales_new] >> join_erp
fetch_weather >> clean_weather
[join_erp, clean_weather] >> join_datasets
join_datasets >> train_model >> deploy_model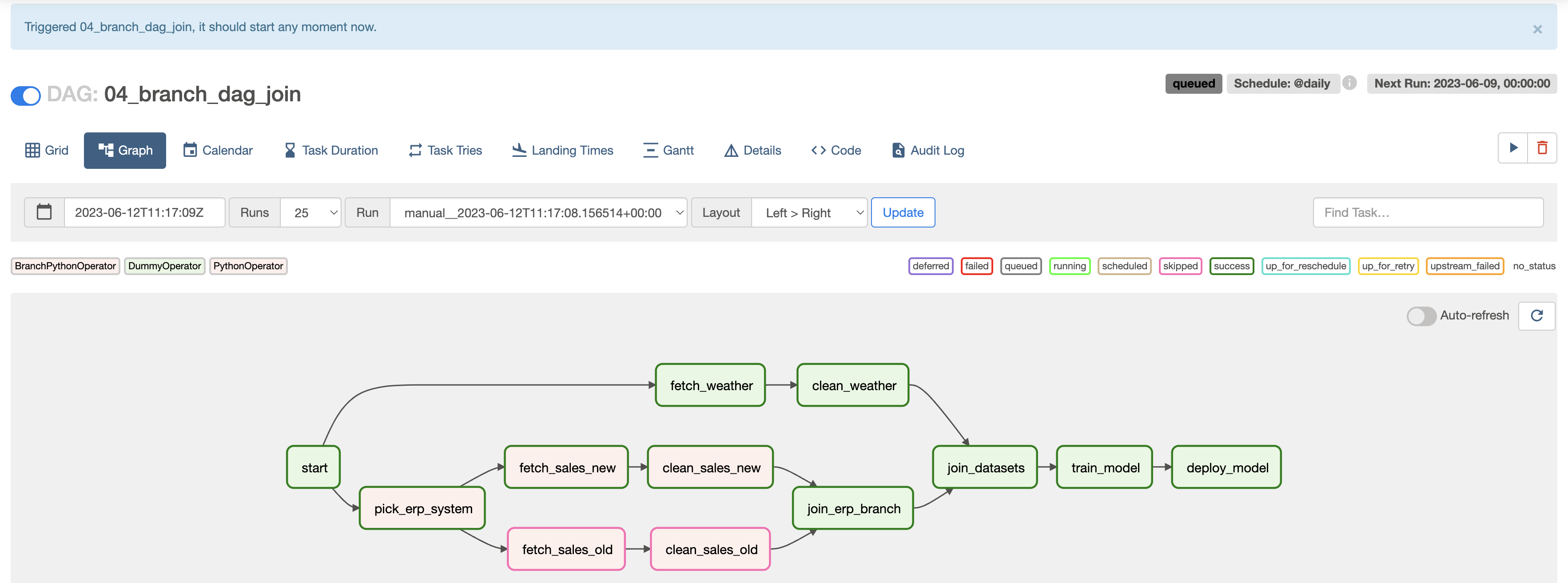
5. 조건부 태스크 만들기
import airflow
import pendulum
from airflow import DAG
from airflow.exceptions import AirflowSkipException
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import PythonOperator, BranchPythonOperator
ERP_CHANGE_DATE = airflow.utils.dates.days_ago(1)
def _pick_erp_system(**context):
if context["execution_date"] < ERP_CHANGE_DATE:
return "fetch_sales_old"
else:
return "fetch_sales_new"
def _latest_only(**context):
# 실행 윈도우에서 경계를 확인합니다.
left_window = context["dag"].following_schedule(context["execution_date"])
right_window = context["dag"].following_schedule(left_window)
# 현재 시간이 윈도우 안에 있는지 확인합니다.
now = pendulum.now("UTC")
if not left_window < now <= right_window:
raise AirflowSkipException()
with DAG(
dag_id="06_condition_dag",
start_date=airflow.utils.dates.days_ago(3),
schedule_interval="@daily",
) as dag:
start = DummyOperator(task_id="start")
pick_erp = BranchPythonOperator(
task_id="pick_erp_system", python_callable=_pick_erp_system
)
fetch_sales_old = DummyOperator(task_id="fetch_sales_old")
clean_sales_old = DummyOperator(task_id="clean_sales_old")
fetch_sales_new = DummyOperator(task_id="fetch_sales_new")
clean_sales_new = DummyOperator(task_id="clean_sales_new")
join_erp = DummyOperator(task_id="join_erp_branch", trigger_rule="none_failed")
fetch_weather = DummyOperator(task_id="fetch_weather")
clean_weather = DummyOperator(task_id="clean_weather")
join_datasets = DummyOperator(task_id="join_datasets")
train_model = DummyOperator(task_id="train_model")
latest_only = PythonOperator(task_id="latest_only", python_callable=_latest_only)
deploy_model = DummyOperator(task_id="deploy_model")
start >> [pick_erp, fetch_weather]
pick_erp >> [fetch_sales_old, fetch_sales_new]
fetch_sales_old >> clean_sales_old
fetch_sales_new >> clean_sales_new
[clean_sales_old, clean_sales_new] >> join_erp
fetch_weather >> clean_weather
[join_erp, clean_weather] >> join_datasets
join_datasets >> train_model >> deploy_model
latest_only >> deploy_model- _latest_only라는 조건 함수를 만들어 가장 최근에 실행한 DAG를 제외하고 모두 실행되지 않게 합니다.
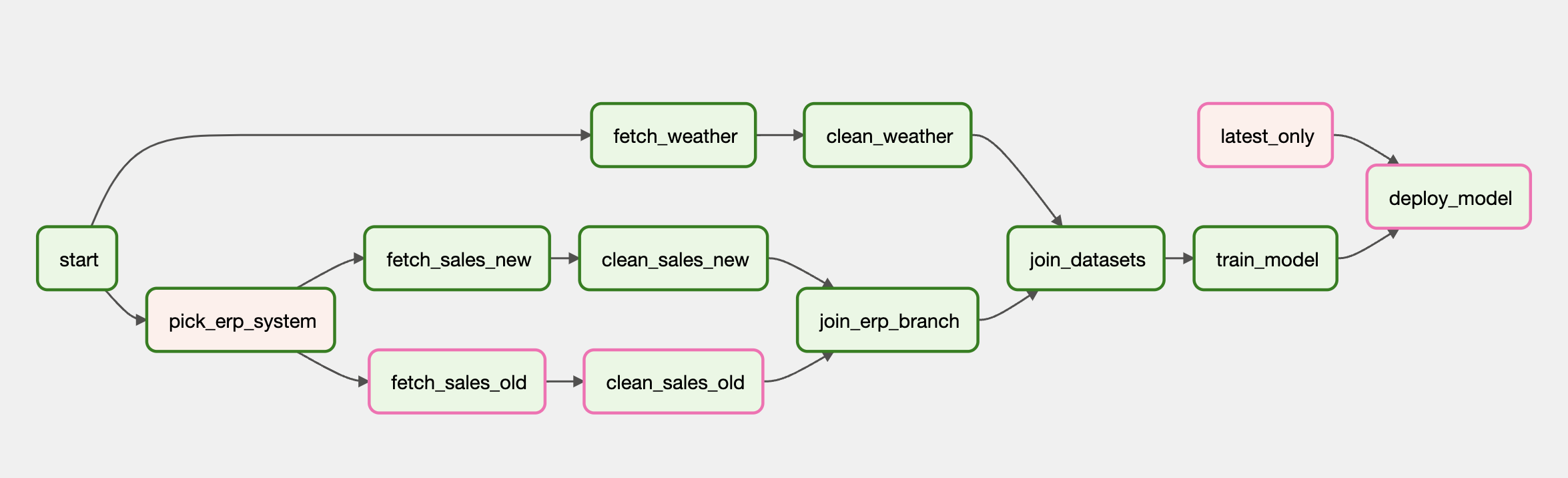
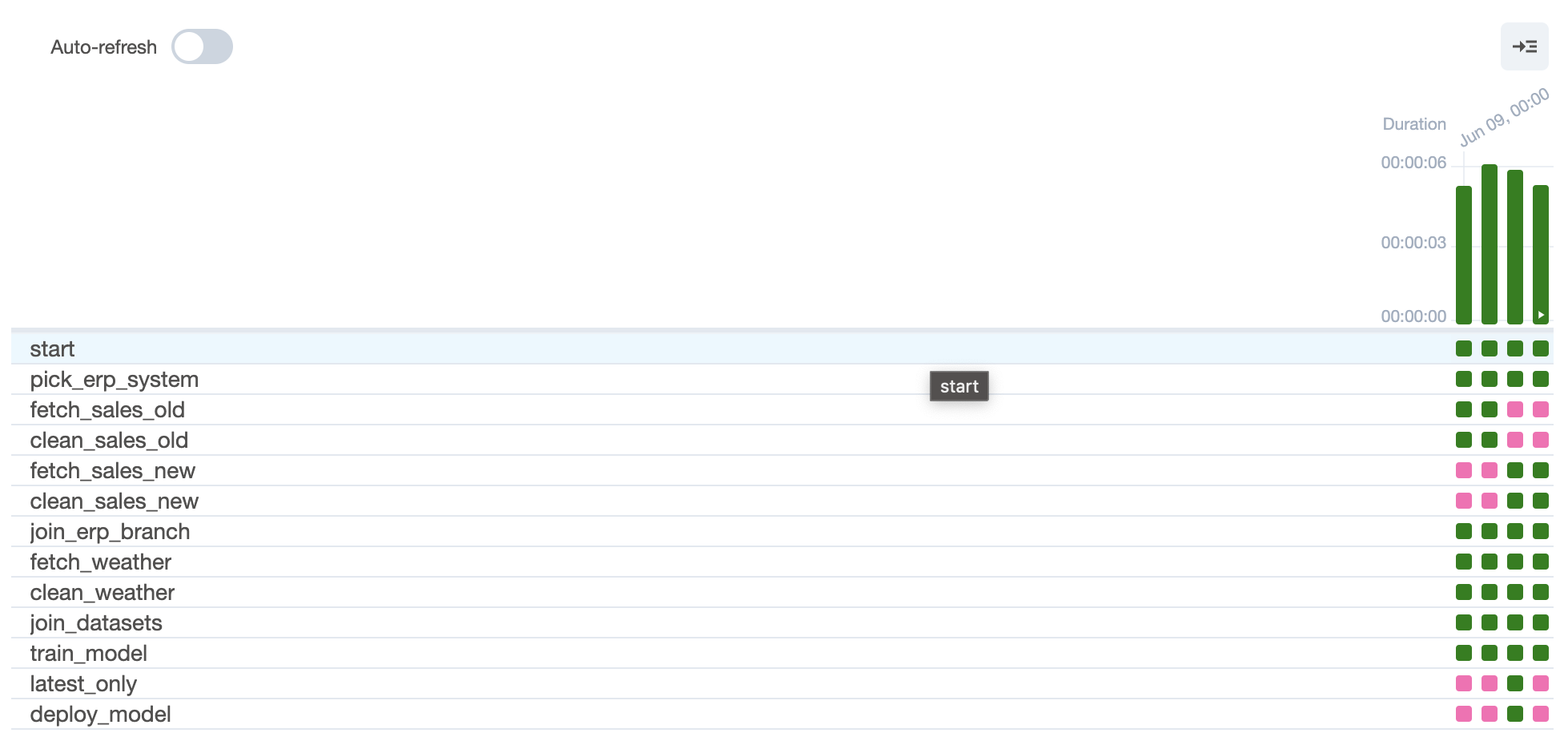
- _latest_only 함수에 의해 하나의 작업만 배포가 되고 나머지는 skip한걸 확인할 수 있습니다.
- 내장 오퍼레이터 사용하기
#latest_only = PythonOperator(task_id="latest_only", python_callable=_latest_only)
# LatestOnlyOperator 오퍼레이터를 통해 같은 효과를 확인할 수 있습니다.
# LatestOnlyOperator 를 사용하면 조건부 배포를 구현하기 간단할 수 있지만
# 복잡한 경우에는 PythonOperator 기반으로 구현하는 것이 효율적입니다.
latest_only = LatestOnlyOperator(task_id="latest_only", dag=dag)
6. 트리거 규칙 정리
| 트리거 규칙 | 동작 | 사용사례 |
| all_success (default) |
모든 상위 태스크가 성공적으로 완료되면 트리거 됩니다. | 일반적인 워크플로에 대한 기본 트리거 규칙입니다. |
| all_failed | 모든 상위 태스크가 실패했거나 상위 태스크의 오류로 인해 실패했을 경우 트리거 됩니다. | 태스크 그룹에서 하나 이상 실패가 예상되는 상황에서 오류 처리 코드를 트리거 합니다. |
| all_done | 결과 상태에 관계없이 모든 무보가 실행을 완료하면 트리거 됩니다. | 모든 태스크가 완료되었을 때 실행할 청소 코드를 실행합니다.(예: 시스템 종료 또는 클러스터 중지). |
| one_failed | 하나 이상의 상위 태스크가 실패하자마자 트리거되며 다른 상위 태스크의 실행 완료를 기다리지 않습니다. | 알림 또는 롤백과 같은 일부 오류 처리 코드를 빠르게 트리거합니다. |
| one_success | 한 부모가 성공하자마자 트리거되며 다른 상위 태스크의 실행 완료를 기다리지 않습니다. | 하나의 결과를 사용할 수 있게 되는 즉시 다운스트림 연산/알림을 빠르게 트리거합니다. |
| none_failed | 실패한 상위 태스크가 없지만, 태스크가 성공 또는 건너뛴 경우 트리거됩니다. | DAG상 조건부 브랜치의 결합에 사용합니다. |
7. 태스크 간 데이터 공유
- XCom을 사용하여 데이터 공유하기
import uuid
import airflow
from airflow import DAG
from airflow.operators.dummy import DummyOperator
from airflow.operators.python import PythonOperator
def _train_model(**context):
model_id = str(uuid.uuid4())
# xcom_push 메서드를 사용하여 데이터 공유하기
context["task_instance"].xcom_push(key="model_id", value=model_id)
def _deploy_model(**context):
# xcom_pull 메서드를 사용하여 XCom을 확인하기
model_id = context["task_instance"].xcom_pull(
task_ids="train_model", key="model_id"
)
print(f"Deploying model {model_id}")
with DAG(
dag_id="10_xcoms",
start_date=airflow.utils.dates.days_ago(3),
schedule_interval="@daily",
) as dag:
start = DummyOperator(task_id="start")
fetch_sales = DummyOperator(task_id="fetch_sales")
clean_sales = DummyOperator(task_id="clean_sales")
fetch_weather = DummyOperator(task_id="fetch_weather")
clean_weather = DummyOperator(task_id="clean_weather")
join_datasets = DummyOperator(task_id="join_datasets")
train_model = PythonOperator(task_id="train_model", python_callable=_train_model)
deploy_model = PythonOperator(task_id="deploy_model", python_callable=_deploy_model)
start >> [fetch_sales, fetch_weather]
fetch_sales >> clean_sales
fetch_weather >> clean_weather
[clean_sales, clean_weather] >> join_datasets
join_datasets >> train_model >> deploy_model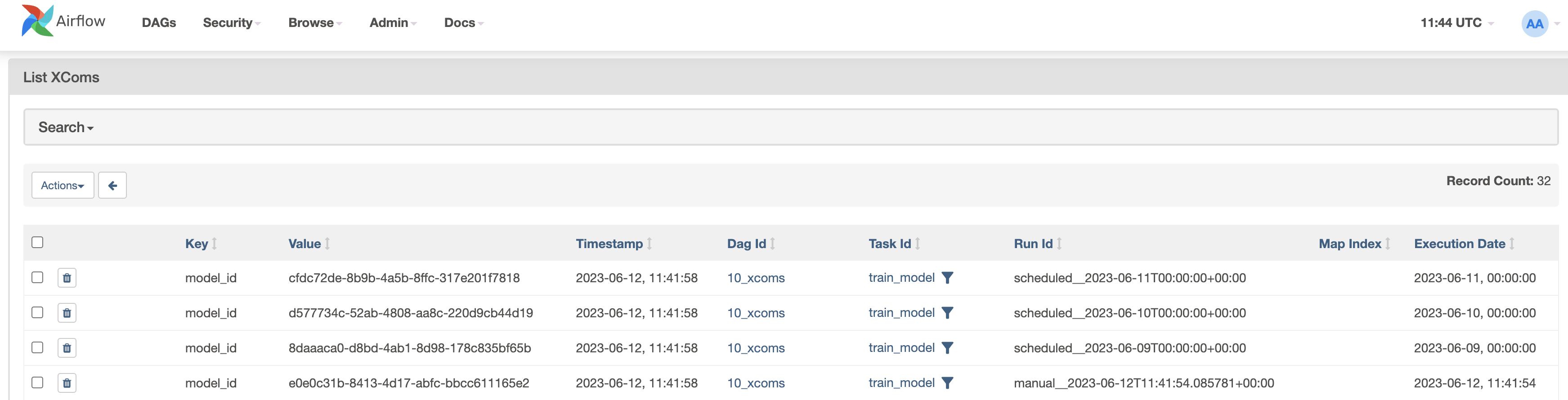
# 템플릿을 통해 XCom 값을 참조 할 수 있습니다.
def _deploy_model(templates_dict, **context):
model_id = templates_dict["model_id"]
print(f"Deploying model {model_id}")
deploy_model = PythonOperator(
task_id="deploy_model",
python_callable=_deploy_model,
templates_dict={
"model_id": "{{task_instance.xcom_pull(task_ids='train_model', key='model_id')}}"
},
)
* XCom 사용 시 고려사항.
- 사이즈 제한: XCom은 메타데이터 데이터베이스에 데이터를 저장합니다. 일반적으로 이러한 데이터베이스는 대량의 데이터를 저장하도록 설계되지 않았기 때문에, 너무 큰 데이터를 XCom으로 전달하려고 하면 성능 문제가 발생할 수 있습니다. 따라서 XCom은 작은 양의 데이터를 전달하는데 사용해야 합니다.
- 직렬화: XCom을 통해 전달되는 값은 직렬화되어야 합니다. 즉, 메모리에 저장된 객체를 바이트 스트림으로 변환할 수 있어야 합니다. 따라서 XCom에는 직렬화 가능한 데이터 타입만 사용해야 합니다.
- 암호화와 보안: XCom은 메타데이터 데이터베이스에 데이터를 저장하기 때문에, 민감한 정보는 암호화되거나 다른 방법으로 보호되어야 합니다.
- 캡슐화: 한 작업에서 생성된 데이터는 그 작업에서만 알아야 할 내용을 포함하고 있을 수 있습니다. 이런 데이터를 다른 작업에게 공개하면, 작업 간의 독립성이 깨질 수 있습니다. 따라서 XCom을 사용할 때는 작업 간의 캡슐화를 고려해야 합니다.
- 의존성 관리: XCom은 작업 간의 의존성을 늘릴 수 있습니다. 한 작업이 XCom을 통해 데이터를 전달하면, 다른 작업이 그 데이터에 의존하게 됩니다. 이러한 의존성이 복잡하게 얽히면, 코드를 이해하고 유지보수하는 것이 어려워질 수 있습니다.
따라서 XCom은 신중하게 사용해야 하며, 필요한 경우에만 사용하고, 가능하면 대안을 찾는 것이 좋습니다. 예를 들어, 한 작업이 생성한 큰 데이터를 다른 작업에서 사용해야 하는 경우, 이 데이터를 공유 파일 시스템이나 분산 스토리지에 저장하고, 이 위치를 XCom으로 전달하는 방법을 고려할 수 있습니다.
* 커스텀 XCom 백엔드 사용하기
Airflow 2.1.0부터 XCom에 커스텀 백엔드를 사용할 수 있게 되었습니다. 커스텀 백엔드를 사용하면, XCom 데이터를 기본 메타데이터 데이터베이스 대신 다른 위치에 저장할 수 있습니다. 이를 통해 XCom의 크기 제한과 관련된 문제를 완화할 수 있습니다.
커스텀 XCom 백엔드를 사용하는 방법은 다음과 같습니다.
- 먼저, XCom 백엔드를 정의하는 Python 모듈을 작성합니다. 이 모듈에는 xcom_push와 xcom_pull이라는 두 개의 함수가 있어야 합니다. xcom_push 함수는 XCom 값을 저장하고, xcom_pull 함수는 XCom 값을 불러오는 역할을 합니다.
예를 들어, 다음과 같이 XCom 데이터를 S3에 저장하는 백엔드를 정의할 수 있습니다:
# my_xcom_backend.py
import boto3
from airflow.models.xcom import BaseXCom
class S3XComBackend(BaseXCom):
PREFIX = "xcom_s3://"
@staticmethod
def serialize_value(value):
return BaseXCom.serialize_value(value)
@staticmethod
def deserialize_value(result) -> Any:
return BaseXCom.deserialize_value(result)
@classmethod
def xcom_push(cls, key, value):
s3 = boto3.client('s3')
value = cls.serialize_value(value)
s3.put_object(Bucket='my-bucket', Key=f"{cls.PREFIX}{key}", Body=value)
@classmethod
def xcom_pull(cls, key):
s3 = boto3.client('s3')
result = s3.get_object(Bucket='my-bucket', Key=f"{cls.PREFIX}{key}")
value = result['Body'].read()
return cls.deserialize_value(value)이 코드는 XCom 데이터를 S3 버킷에 저장하고 불러옵니다. my-bucket은 실제 S3 버킷 이름으로 변경해야 합니다.
2. 그런 다음, Airflow 구성에서 xcom_backend 옵션을 사용하여 커스텀 백엔드를 지정합니다. 이 옵션은 Airflow 구성의 [core] 섹션에 위치해야 합니다.
[core]
xcom_backend = my_xcom_backend.S3XComBackend이 설정은 my_xcom_backend.py 파일의 S3XComBackend 클래스를 XCom 백엔드로 사용하도록 지시합니다.
이렇게 하면, Airflow는 XCom 데이터를 기본 메타데이터 데이터베이스 대신 S3에 저장하고 불러옵니다.
참고로, 위의 코드는 예시를 위한 것으로, 실제 환경에서는 S3에 접근하는 데 필요한 인증 정보 등을 적절히 처리해야 합니다.
8. Taskflow API로 파이썬 태스크 단순화 하기
import uuid
import airflow
from airflow import DAG
from airflow.decorators import task
from airflow.operators.dummy import DummyOperator
with DAG(
dag_id="13_taskflow_full",
start_date=airflow.utils.dates.days_ago(3),
schedule_interval="@daily",
) as dag:
start = DummyOperator(task_id="start")
fetch_sales = DummyOperator(task_id="fetch_sales")
clean_sales = DummyOperator(task_id="clean_sales")
fetch_weather = DummyOperator(task_id="fetch_weather")
clean_weather = DummyOperator(task_id="clean_weather")
join_datasets = DummyOperator(task_id="join_datasets")
start >> [fetch_sales, fetch_weather]
fetch_sales >> clean_sales
fetch_weather >> clean_weather
[clean_sales, clean_weather] >> join_datasets
# @task 데코레이션을 통해 함수를 태스크로 만들어
# 태스크를 연결합니다.
# model_id를 더이상 XCom에 공유 되지 않습니다.
@task
def train_model():
model_id = str(uuid.uuid4())
return model_id
@task
def deploy_model(model_id: str):
print(f"Deploying model {model_id}")
model_id = train_model()
deploy_model(model_id)
join_datasets >> model_id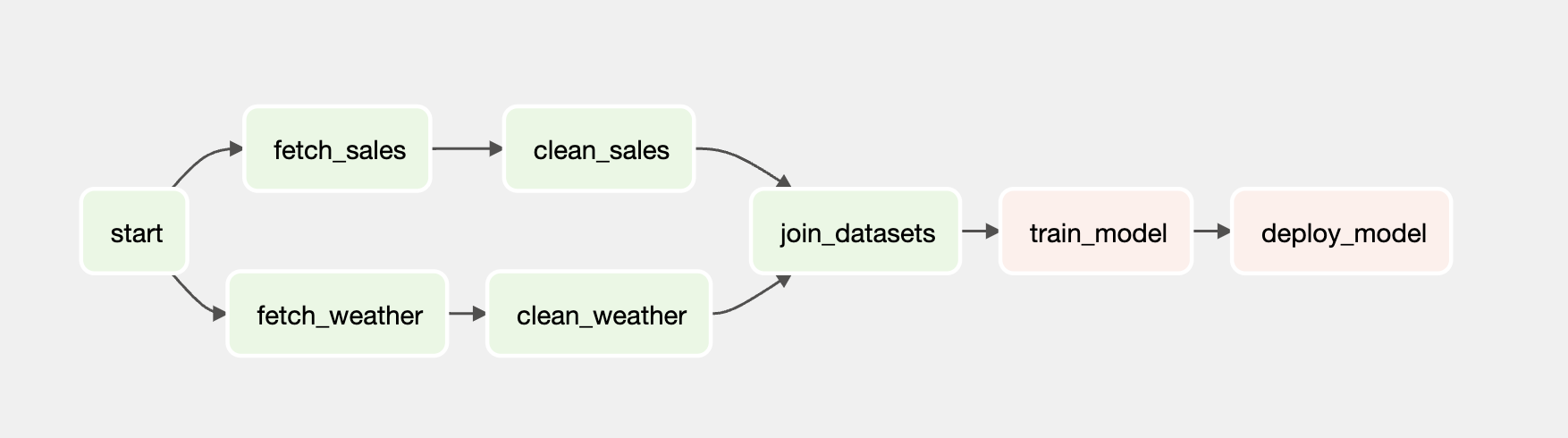
- @task 데코레이션을 통해 함수가 task가 됐고, 의존성이 연결된걸 확인 할 수 있습니다.
'파이썬 > Airflow' 카테고리의 다른 글
| 워크플로 트리거 (0) | 2023.06.18 |
|---|---|
| Airflow 콘텍스트를 사용하여 태스크 템플릿 작업하기 (0) | 2023.06.12 |
| Airflow 스케줄링 (0) | 2023.06.11 |
| 첫번째 DAG 작성 (0) | 2023.06.11 |
| Airflow가 뭔가요? (0) | 2023.06.11 |

